We recently switched from Otto v3 to OttoFMS for a 20 server solution. All OttoFMS versions are 4.3.0 except for the dev (“from”) server, which is v4.3.1.
Otto v3 is still installed on all servers but I’ve been told that this is OK unless you try to run both versions simultaneously.
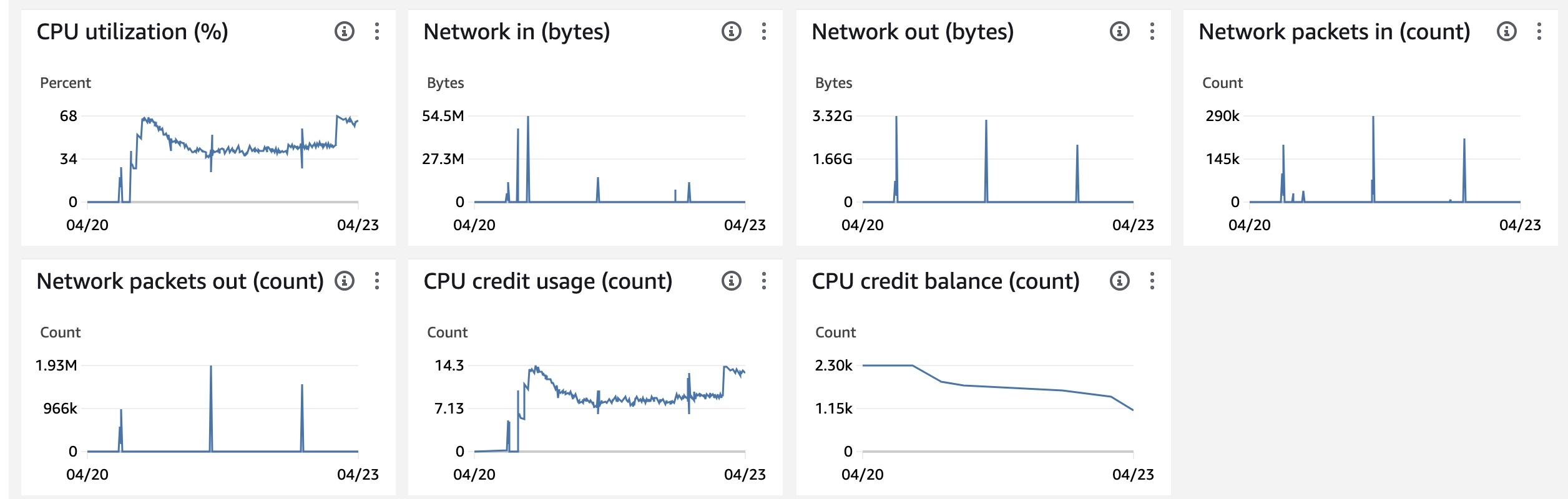
For the latest deployment, most of the servers took a matter of a few hours while the longest ones took up to 10 hours. Except… one server (Ubuntu Linux / 3rd party host) is apparently still Migrating nearly 60 hours after start time. I have “Show full log” turned on and can see many successful file migrations (there are 8 files total). Currently it’s working on the largest file (19.5 GB), and has been for over a day. Again, this is highly abnormal.
CPU has been busy this whole time, hovering between 30-40% usage initially but lately it’s up around 60%. It is on AWS EC2, but I confirmed that the CPU credit usage is still above 0, so there shouldn’t be any artificial throttling going on there.
I perused the four OttoFMS logs and nothing stood out.
So… what should I do? Abort the deployment? Let it continue working?
p.s. As an aside, here’s a bug report: The Duration timer appears to roll over every 24 hours and start from zero. At this point in time it should say “59:27:17”, but it actually says “11:27:17”.
I found that the t series was having issues and moved to c5 instead (I’m guessing you are using t because of the credits). I think the bursting does/did something during the long process, and then it got grumpy, I could be wrong but the COMPUTE optimized Cs (large and extra large) seem more stable, and were faster overall. I also found that I could push the memory usage to the max, and as well as maxing out concurrencies for faster migrations. Your mileage may very.
That all being said, we didn’t come from 3.0, and We’re still getting the hang of it.
**Note that I originally wrote “Memory Optimized” that was wrong. C-types are compute optimized. I wanted more processors to try do more concurrent migration. This worked well
Thanks @Operadad. Good thoughts… yes I’m sure we’re using either a t2 or t3; I don’t have direct control to this particular server so I’m reliant on my server vendor for help.
What’s confusing is that similarly configured servers were able to complete similarly sized migrations in much less time.
This “runaway” migration actually did finish last night without error, roughly 72 hours after it started. OttoFMS says the duration was “23:01:26”, but it really was almost 72 hours.
I talked to some people in our infrastructure team. Here is what I learned.
Once you are throttled you will be throttled until your usage goes to zero. But you will never go to zero while a migration is running. The Data Migration Tool is going to use all available resources until it is done.
So if you don’t get throttled a migration might complete in a normal amount of time. But once you get throttled you will stay throttled until the migrations are done!
AWS T-Types are not appropriate for FileMaker Server with or with out OttoFMS.
@HighPower_Matt, You are correct, OttoFMS seems to be limited in its clock with my Testing system I too went over 24 hours and the total timer reset back to zero; however, we didn’t let it go 72 hours only about 36. This was ridiculous and even @toddgeist was like “it may take a while but we have 30GB files finishing in a much shorter time.” (or some such, I’m too lazy to look it up). That’s when I got the idea to try a different Instance type. I did not know about the T series “once it throttles, it stays throttled” behavior, but I figure it must have something to do with it.
Once I switched to a non burstable instance (in our case C5) then things really began to improve. I watched migration times come way down. Now, per Todd’s comment about T-types being used for any FileMaker Server, I’m wondering if I can convince some powers that be to try moving more of our FMServers away from them. That being said, the t4g is a very cost effective server, and can save a lot of money, especially on a non-production machine.
This is great information y’all, thanks for the insights! I just want to let y’all know I have fixed the clock issue in the next version of OttoFMS, it should now properly roll over to 24 instead of reseting back to 0. Thank you!
@toddgeist and @Operadad I believe you when it comes to EC2 T-types, but I’m trying to find a good config and will have to weigh things carefully. Money is oftentimes an important factor.
What’s hilarious about this situation is that hours after this migration completed, the client provided me with a new file to upload… the same one that OttoFMS was migrating for days.
I hope you can understand that our advice to any problems having to do with speed or perceived stalling out of migraions on burst-able compute is going to be that you need to upgrade your compute to non burst-able types with the proper specs.
Our reasoning is pretty simple. When you move off bust-able compute these problems go away. Therefor we conclude that these types are not suitable for FileMaker server hosting or running OttoFMS.
Sorry to be a bummer. I wish we could make this stuff run on cheaper compute. But our hands are tied
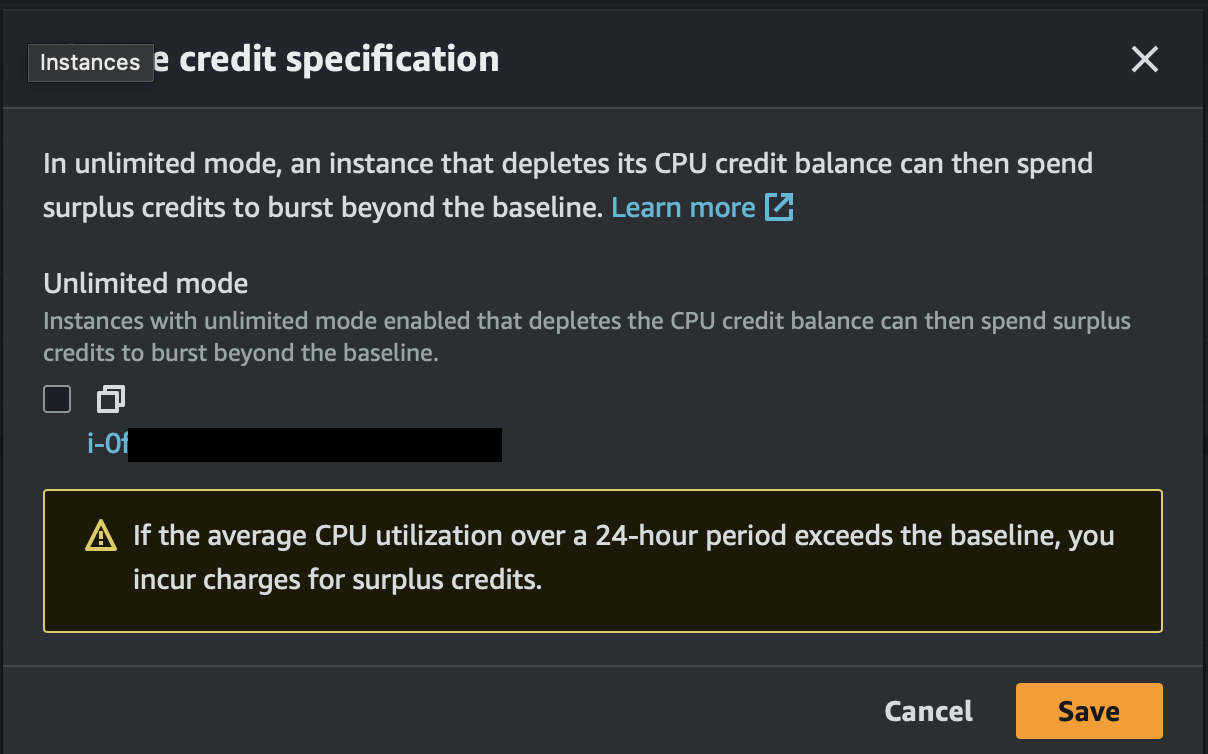
One possibility you can try is to set the credit specification to “unlimited.” In theory, if bursting, and you run out of credits, it will keep in the bursting state and AWS will just charge you more. Note that with the t4g ARM processor line, the unlimited setting is on by default, but with t2 or t3 you have to select it. I have not experimented with this issue as of yet. Our test environment was set up to mimic our client’s on-premise environment which is x86 with Ubuntu 20.
@Operadad I can tell you’re a solid dude. Posting helpful info + screenshots of examples is great.
This particular server is out of my direct control, but what you’re describing is almost exactly what I have been playing with on another server… t3.xlarge with Ubuntu 22.04 / x86. I had not heard of the t4g instance types yet.
Amazon EC2 T4g instances are powered by Arm-based AWS Graviton2 processors. T4g instances are the next generation low cost burstable general purpose instance type that provide a baseline level of CPU performance with the ability to burst CPU usage at any time for as long as required. They deliver up to 40% better price performance over T3 instances and are ideal for running applications with moderate CPU usage that experience temporary spikes in usage.
The only issue I can find with them is that Base Elements plugin is not yet compiled for ARM!!